Introduction to Fluentd
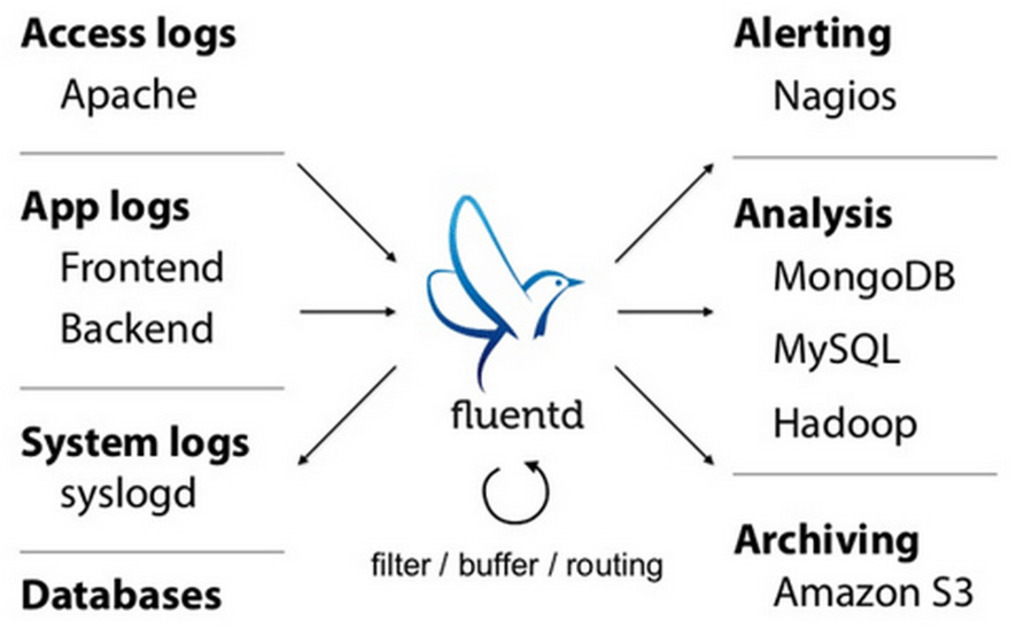
The legacy logging infrastructure we have to deal with today was designed for humans and not machines, so a lot of effort is wasted trying to make backend systems understand log data. Logs were designed for us, so we could look at debug data and stack traces and figure out what was going on with our application. This was perfectly fine when we were dealing with a small amount of data. But now that we are deploying huge systems with many moving parts, we can no longer parse the information these systems produce. The primary consumers of log data has shifted from humans to machines. The problem is that our applications and systems produce logs in different formats and aren’t exactly extensible.
Fluentd attempts to solve this problem by doing two things. First, it provides a unified logging layer to separate the data sources from backend systems, thereby providing a single standard format for logs (it produces logs in JSON format). Secondly, it provides a plugin-based architecture which allows us to pretty much do whatever we want with our logs. So now we can get machines to handle our logs, and add intelligence which would decide when a human needs to get involved in the mix. It allows us to deploy a distributed system to handle logs.
Some of Fluentd’s features are as follows:
- Most performance sensitive parts are written in C, with Ruby as a wrapper. Ruby provides flexibility and extensibility and adds functionality.
- It is scalable and reliable. Supports memory-based buffering, file-based buffering (has resume support), robust failover and can be configured for HA. Fluentd can handle failure and retries automatically.
- It tags data, and routes data based on tags.
- Has client libraries for Java, PHP, Python, Per, Ruby, etc. Fluentd supports most of the common programming languages. Fluentd can unify the logging mechanism from multiple applications written in different languages, deployed at different data centres. The logger libraries are easy to install, and lightweight.
- Stores things as JSON. Fluentd tries to structure data as JSON as much as possible: this allows Fluentd to unify all facets of processing log data: collecting, filtering, buffering, and outputting logs across multiple sources and destinations. The downstream data processing is much easier with JSON, since it has enough structure to be accessible while retaining flexible schemas.
- The backend system is fully decoupled from the logging system.
- Many Fluentd nodes can partially aggregate data and forward them to other Fluentd nodes for further processing, storage, etc.
In order to understand what Fluentd is all about, you will have to remember that logs are streams, and not files.
Architecture
Some History
Just after Sada co-founded Treasure Data, Inc, he found that a lot of data (especially time-series data) was not used effectively because there’s no easy solution to reliably collect it. He wanted to invent ‘easy’ and ‘flexible’ solution to unity the data collection, with machine-readable format. That’s how Fluentd was born. Sada is a co-founder of Treasure Data, Inc., a primary sponsor of the Fluentd project. Since open-sourced in October 2011, the Fluentd project has grown dramatically: dozens of contributors, hundreds of community-contributed plugins, thousands of users, and trillions of events collected, filtered and stored. Currently Masahiro “Masa” Nakagawa is the main maintainer. The first commit was June 2011.
Installing Fluentd
Fluentd’s installation is pretty straightforward so I won’t repeat it here. See here: http://docs.fluentd.org/v0.12/categories/installation Be sure to read the pre-installation notes here: http://docs.fluentd.org/articles/before-install
Getting Started
So you’ve read up Fluentd, and decided that you like it. And now you want to see it in action. A Fluentd configuration generally contains two sections: a source, which defines where the actual log stream will come from, and a match, which decides what to do with the log stream once it arrives. There are two examples below which will explain this well.
Example 1: Writing Apache Access Logs with Fluentd
Find your Fluentd configuration file (located /etc/td-agent/td-agent.conf) and add the following lines to it.
<source>
@type tail #We are using the in_tail module of Fluentd
path /var/log/httpd/access_log # Location of Apache access log
pos_file /var/log/td-agent/httpd-access.log.pos # Where to record file position
tag apache.access # FluentD tag. This is used in the match section to process logs further.
format apache2 # apache2 is a predefined format. You can add your own regex here.
</source>
<match apache.access>
@type file # We are using the out_file module of Fluentd. This will store the incoming stream in a file.
path /tmp/my-fluent-app
time_slice_format %Y%m%d
time_slice_wait 10m
time_format %Y%m%dT%H%M%S%z
utc
</match>
Then restart Fluentd.
If everything is fine, you should have a new file in your /tmp directory where Fluentd logs would show up in JSON format. If that’s not the case, make sure you send some traffic to Apache so some access logs can be generated. If that fails, check out Fluentd logs in /var/log/td-agent/td-agent.log.
Example 2: Forwarding Events from one Fluentd to another
Add the following configuration to the first server.
<source>
@type tail
path /var/log/httpd/access_log #...or where you placed your Apache access log
pos_file /var/log/td-agent/httpd-access.log.pos # This is where you record file position
tag apache.access #fluentd tag!
format apache2 # Do you have a custom format? You can write your own regex.
</source>
<match apache.access>
@type forward
send_timeout 1s
recover_wait 10s
heartbeat_interval 1s
phi_threshold 16
hard_timeout 60s
<server>
name box1 # Name of second server used in logs
host 10.1.1.61 # IP address for second server
port 24224 # Port of second server where logs are forwarded. This port should be open on second server for both TCP and UDP.
</server>
</match>
Add the following to the second server.
<source>
@type forward
port 24224
</source>
<match *.**>
@type file
path /tmp/my-fluent-app
time_slice_format %Y%m%d
time_slice_wait 10m
time_format %Y%m%dT%H%M%S%z
utc
</match>
Restart Fluentd on both machines and you should see Fluentd events forwarded from the first Fluentd instance to the second one. Be sure to activate some traffic so logs can be generated. As always you can check the logs for any problems. Be sure to open Fluentd ports for TCP and UDP on the second server.
The above two examples shouldn’t be used on production, but they should get you started.
And that’s it! Let me know what you think.
Have fun using Fluentd :)
Resources
- http://www.slideshare.net/tagomoris/rubykaigi-2013-111130
- http://www.slideshare.net/sylvainkalache/fluentd-at-slideshare
- http://www.slideshare.net/tagomoris/log-analysis-with-hadoop-in-livedoor-2013
- http://www.slideshare.net/frsyuki/how-24042353
- http://www.slideshare.net/sematext/solr-for-indexing-and-searching-logs

Help me fuel up so I can keep typing typing typing...
&emoji=☕&slug=ayushsharma&button_colour=FFDD00&font_colour=000000&font_family=Cookie&outline_colour=000000&coffee_colour=ffffff)
